Regular Expressions (regex) in Linux are powerful patterns used for searching, matching, and manipulating text. They provide a flexible and concise way to express complex search patterns. Regular expressions are supported by various Linux command-line tools, such as grep, rename, sed, awk, and perl, allowing for advanced text processing.
Here are some useful tools available in Regular Expression
- grep
- rename
- sed
- awk
- perl
The “grep” command in Linux is a versatile tool that searches for patterns within files or input data. It is commonly used with regular expressions to perform advanced pattern matching and filtering. When using “grep” with regular expressions, you can search for specific patterns by providing a regular expression as the search pattern. “grep” will then match and display any lines that contain the pattern.
Here are a few examples of using “grep” with regular expressions:
Search for lines containing a specific word:
Syntax: grep ‘pattern’ filename (This will search for the word ‘pattern’ in the file filename and display any lines that contain it.)

Search for lines starting with a specific pattern:
Syntax: grep ‘^pattern’ filename (This will match and display lines that start with the word ‘pattern’ in the file filename.)

Search for lines ending with a specific pattern:
Syntax: grep ‘pattern$’ filename (This will match and display lines that end with the word ‘pattern’ in the file filename.)
The “rename” command in regular expression in Linux allows you to rename multiple files at once using regular expressions. It is a powerful tool for batch renaming files based on specific patterns.
The basic syntax of the rename command is as follows:
Syntax: rename [options] ‘s/old_pattern/new_pattern/’ files (Here, old_pattern is the regular expression pattern you want to match in the original file names, and new_pattern is the replacement pattern for renaming the files. The s/ at the beginning denotes a substitution operation.)
Here are a few examples to illustrate the usage of the rename command with regular expressions:
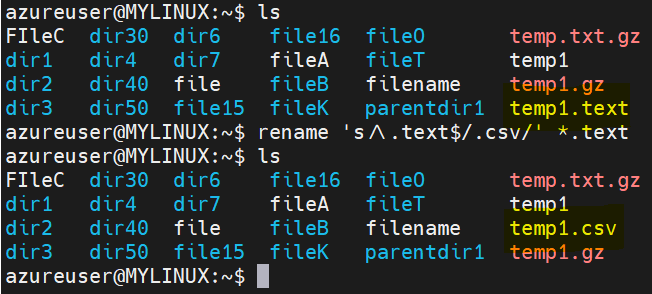
Rename files with a specific extension:
Syntax: rename ‘s/.txt$/.csv/’ *.txt (This command renames all files with the .txt extension to have the .csv extension.)
The “sed” command in regular expression in Linux is a powerful stream editor that can perform text transformations and modifications using regular expressions. It allows you to modify text in files or from standard input based on specified patterns. When using “sed” with regular expressions, you can perform various operations, such as substitution, deletion, insertion, and more.
The basic syntax of the “sed” command is as follows:
Syntax: sed options ‘s/pattern/replacement/flags’ filename (Here, pattern represents the regular expression pattern you want to match, replacement is the text or pattern to replace the matched pattern, and flags are optional flags to modify the behavior of the substitution.)
Here are a few examples of using “sed” with regular expressions:
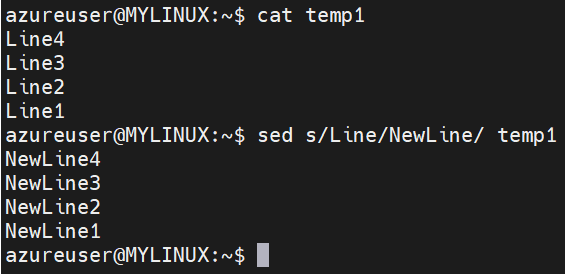
Substitute a word in a file:
Syntax: sed ‘s/old_word/new_word/’ filename (This command replaces the first occurrence of old_word with new_word on each line of the file filename.)
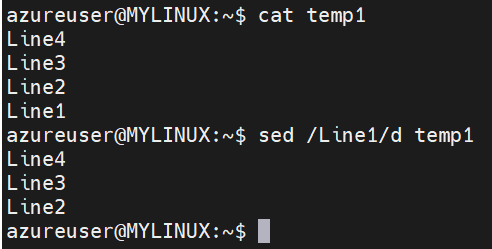
Delete lines matching a pattern:
Syntax: sed ‘/pattern/d’ filename (This command deletes all lines in the file filename that contain the pattern.)
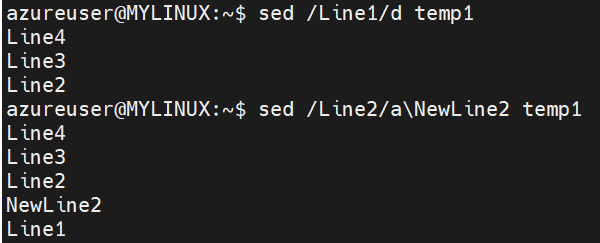
Insert text after a specific pattern:
Syntax: sed ‘/pattern/a\inserted_text’ filename (This command inserts inserted_text after each line containing the pattern in the file filename.)
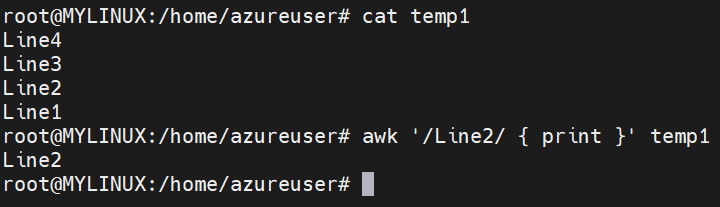
The “awk” command in Linux is a versatile text processing tool that allows you to extract and manipulate data from files or input streams. It supports regular expressions and provides powerful pattern matching and data manipulation capabilities.
With “awk”, you can define patterns and actions to perform on each line of input data. Regular expressions are commonly used within “awk” to specify patterns for matching and selecting specific parts of the input.
The basic syntax of the “awk” command is as follows:
Syntax: awk ‘/pattern/ { action }’ filename (Here, /pattern/ represents the regular expression pattern to match, and action defines the actions to be performed on the lines that match the pattern.)
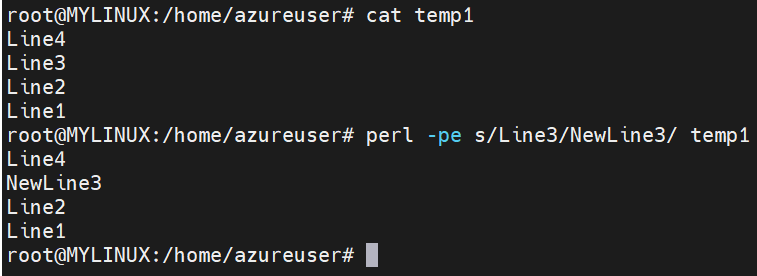
The “perl” command in Linux is a scripting language that provides powerful support for regular expressions. It is often used for text processing, data manipulation, and automation tasks. Perl has extensive regular expression capabilities, offering advanced features and syntax beyond what is provided by other command-line tools. When using “perl” with regular expressions, you can perform complex pattern matching, substitution, and other text manipulation operations.
The basic syntax of the “perl” command with regular expressions is as follows:
Syntax: perl -pe ‘s/pattern/replacement/options’ filename (Here, pattern represents the regular expression pattern to match, replacement is the text or pattern to replace the matched pattern, and options are optional modifiers to control the behavior of the regular expression.)
Wrapping Up Regular Expressions
So, in this section we discussed on various types of regular expression in Linus. The grep, rename, sed, awk, and Perl are powerful tools in Linux for text processing and manipulation using regular expressions. Grep allows for pattern matching and filtering of text. Rename enables batch renaming of files based on regular expressions. Sed provides versatile text transformations and substitutions. Awk allows for pattern-based data extraction and manipulation. Perl offers advanced regular expression capabilities for complex text processing tasks. If you wish to learn more on this topic, follow here or want to learn different tools available in Linux, please follow here.