Linux, known for its open-source nature and unparalleled flexibility, has become a dominant force in the world of operating systems.
However, understanding Linux can be challenging for both beginners and experienced users. In this article, we aim to provide expert answers to top 50 Linux questions and answers, unraveling the mysteries surrounding the platform. Whether you’re a curious beginner or a seasoned Linux enthusiast seeking clarification on specific concepts, this comprehensive guide will deepen your understanding of the Linux ecosystem.
1. What is Linux?
Linux is an open-source operating system kernel that serves as the foundation for a wide range of operating systems commonly referred to as “Linux distributions.” Created by Linus Torvalds in 1991, Linux was initially developed as a free and open alternative to proprietary operating systems.
Linux is known for its stability, security, and flexibility, and it has gained immense popularity across various domains, from servers and supercomputers to embedded devices and smartphones. It follows a modular design, allowing users to customize and configure their systems according to their specific needs.
Linux is an open-source operating system kernel that serves as the foundation for a wide range of operating systems commonly referred to as “Linux distributions.” Created by Linus Torvalds in 1991, Linux was initially developed as a free and open alternative to proprietary operating systems.
Linux is commonly known for its “security”, “stability” and “flexibility”, and it has gained popularity across various domains, from servers and supercomputers to embedded devices and smartphones. It follows a modular design, allowing users to customize and configure their systems according to their specific needs.
One of the notable features of Linux is its strong support for multi-user and multitasking capabilities. It provides a command-line interface, commonly known as the shell, as well as graphical user interfaces (GUIs) through desktop environments like GNOME and KDE.
As an open-source project, Linux benefits from a vast community of developers and contributors worldwide who collaborate to improve and expand its functionalities. This collaborative nature has fostered a rich ecosystem of software, applications, and tools that are freely available for users.
Overall, Linux has become a powerful and versatile operating system that has revolutionized the software landscape, offering stability, customization options, and a wealth of resources to its users.
2. What are the components of the Linux system?
The Linux system consists of several key components that work together to provide its functionality. Here are the main components of the Linux system:
Kernel: The Linux kernel is the core component of the operating system. It provides essential services, such as “hardware details”, “process management”, “memory management”, “device drivers”, and “system calls”. The kernel interacts directly with the underlying hardware and acts as a bridge between software applications and the hardware resources.
Shell: The shell is a command-line interface that allows users to interact with the operating system. It interprets user commands and executes them. Popular shells in Linux include Bash (Bourne Again Shell), C shell, and Korn shell. The shell provides powerful scripting capabilities and allows users to automate tasks and create complex command sequences.
File System: Linux uses a hierarchical file system that organizes files and directories in a tree-like structure. The most commonly used file system in Linux is the Extended File System (ext), with ext4 being the latest version. Other file systems like Btrfs, XFS, and JFS are also supported. The file system handles file storage, access, and management.
Libraries: Linux includes a vast collection of software libraries that provide reusable functions and code for developers. These libraries, such as the GNU C Library (glibc), provide programming interfaces and essential functions that allow applications to interact with the kernel and access various system resources.
Utilities: Linux offers a wide range of command-line utilities and tools that perform various tasks, including file manipulation, text processing, network configuration, process management, system monitoring, and more. Examples of common Linux utilities include ls, cp, mv, grep, sed, awk, and tar.
Graphical User Interface (GUI): While Linux can be used through the command-line interface, it also supports GUIs that provide a visual and intuitive way to interact with the system. Popular Linux desktop environments include GNOME, KDE Plasma, Xfce, and LXQt, which offer graphical interfaces, window managers, and desktop environments for users to customize their experience.
These components work together to create a robust and versatile operating system that powers a diverse range of devices and applications.
3. What is CLI?
CLI stands for Command-Line Interface. It is a text-based interface used to interact with a computer operating system or software application by entering commands and receiving textual output. In a CLI, the user interacts with the system by typing specific commands rather than using graphical elements like buttons and menus.
In a CLI, the user typically enters commands using a keyboard, and the system responds with textual output displayed on the screen. This type of interface has been a fundamental part of computing for decades and is still widely used today.
CLI provides direct access to system functionality and allows for precise control and automation of tasks. It is often favored by experienced users and system administrators for its efficiency, flexibility, and the ability to perform complex operations using scripting languages.
Examples of popular CLI environments include the command prompt in Windows (CMD or PowerShell) and the Terminal in Unix-like systems (such as Linux and macOS). In these interfaces, users can execute a wide range of commands to perform tasks like file management, software installation, system configuration, and more.
4. What is LILO?
LILO (LInux LOader) is a bootloader used in older versions of Linux distributions. It was commonly used before the advent of GRUB (GRand Unified Bootloader). The bootloader is responsible for loading the operating system into memory during the boot process.
LILO was designed to provide a simple and reliable method for booting Linux on x86-based systems. It resided in the Master Boot Record (MBR) or the boot sector of a disk and presented a boot menu that allowed users to choose the desired operating system or kernel to boot.
5. How to find total physical memory available in Linux?
To see total available memory in Linux, execute the below command:
grep MemTotal /proc/meminfo
Here is an example of the above command:

6. What is the maximum length of a file name in Linux?
The maximum number of a file name in Linux is 255 bytes and maximum number of a file name including its path is 4096 bytes.
7. How do I check memory and storage in Linux?
We can use df -H command to check total memory and storage in Linux. Here, df stands ‘disk free’ and h for ‘human readable format’
Here is an example of the above command:

8. How to check free RAM in Linux?
To check RAM usage in Linux, we use free -h command. Here -h is used for human-readable format.
Here is an example of the above command:

9. What is the Linux command for CPU info?
The lscpu command is used to display detailed information about the CPU architecture and characteristics of your Linux system. It provides information such as the number of CPU cores, CPU frequency, cache sizes, and more.
The output of the above command will look like this:
Architecture: The CPU architecture of your system (e.g., x86_64, armv7l).
CPU(s): The number of logical CPUs or cores in your system.
Thread(s) per core: The number of hardware threads per CPU core.
Core(s) per socket: The number of CPU cores per CPU socket.
Socket(s): The number of physical CPU sockets in your system.
Model name: The model or name of your CPU.
CPU MHz: The CPU frequency in megahertz.
Cache sizes: The sizes of different levels of CPU cache (L1, L2, L3).
10. How to check CPU usage on Linux?
To check CPU usage on Linux, we use top command.
After executing the command, the htop interface will appear, displaying real-time information about CPU usage, memory usage, system load, running processes, and more.
The CPU usage is represented by colored bars, and you can see detailed information about each running process, including its PID (Process ID), user, CPU usage, memory consumption, and more.
11. Explain top 5 features of the Linux system?
Linux, as a versatile and powerful operating system, offers numerous features that contribute to its popularity and widespread use. Here are five notable features of the Linux system:
Open Source: Linux is an open-source operating system, which means its source code is freely available to the public. This allows users and developers to view, modify, and distribute the code, fostering a collaborative and transparent environment. Open source nature encourages innovation, flexibility, and community-driven development, leading to a vast ecosystem of software, tools, and distributions.
Stability and Reliability: Linux is basically known for its stability and reliability. It is designed to handle high workloads and operate continuously for extended periods without encountering crashes or performance issues. The modular architecture, robust memory management, and efficient process scheduling contribute to the system’s stability, making it suitable for critical applications and servers.
Security: Linux places a strong emphasis on security. Its multi-user architecture and access control mechanisms provide effective user isolation and privilege management. The permission system ensures fine-grained control over file and directory access. Additionally, regular security updates, extensive auditing capabilities, and a proactive security community contribute to Linux’s reputation as a secure operating system.
Flexibility and Customization: Linux offers unparalleled flexibility and customization options. The modular design of Linux allows users to select and install only the components they require, reducing system bloat. Furthermore, the command-line interface provides granular control over system configuration and customization.
Scalability and Portability: Linux is highly scalable, allowing it to adapt to diverse hardware configurations, from embedded devices and smartphones to servers and supercomputers. It can efficiently utilize resources, distribute workloads, and scale up or down as needed. Moreover, Linux supports a wide range of hardware architectures, making it highly portable and enabling its deployment across different devices and platforms.
These features, among many others, have contributed to the success and widespread adoption of Linux in various domains, including enterprise systems, cloud computing, mobile devices, embedded systems, and scientific research.
12. “What is the use of cron command?”
The cron command, or more accurately the cron daemon, is a time-based job scheduler in Linux and Unix-like operating systems. It allows users to schedule and automate the execution of tasks or commands at specific intervals, such as hourly, daily, weekly, or monthly. The cron daemon constantly runs in the background and triggers the execution of scheduled tasks according to predefined schedules.
The cron command is widely used for automating repetitive tasks, such as system maintenance, backups, log rotation, data synchronization, and more. It simplifies the process of scheduling and executing tasks, allowing users to focus on other important activities.
13. How do I list cron jobs?
To list down all cron jobs for an active users, run the crontab -l command while logged into the account. It shows contents for the active user’s cron file and prints the introductory file information with its cron jobs entries.
14. How do I list cron jobs for a user?
To list down all cron jobs for an users, run the sudo crontab -l -u example-user-name command. It will display all cron jobs scheduled by a specific user but to see others jobs you must have sudo privilege.
15. How do I find all cron files?
To find all cron files on a Linux system, you can check specific directories where cron files are typically located i.e., /var/spool/cron/crontabs/. The cron files determine the scheduled tasks for different users or system services.
16. What is the purpose of the “grep” command in Linux?
The grep command in Linux is a powerful text-searching utility used to search for specific patterns or regular expressions within files or streams of text. The name “grep” stands for “Global Regular Expression Print.”
The primary purpose of the grep command is to search for lines that match a given pattern or regular expression and display them as output. It is commonly used to extract relevant information from files, filter command output, or perform complex text processing tasks.
17. What is the difference between absolute and relative paths in Linux?
In Linux, paths are used to specify the location of files and directories within the file system. The two main types of paths used are absolute paths and relative paths. Here’s the difference between them:
Absolute Path:
An absolute path is a complete and explicit path that specifies the exact location of a file or directory from the root directory (/).
It includes the entire directory hierarchy from the root directory to the target file or directory.
An absolute path always starts with a forward slash (/).
Examples of absolute paths: /home/user/documents/file.txt, /var/log/syslog.
Relative Path:
A relative path specifies the location of a file or directory relative to the current working directory.
It does not start with a forward slash (/) and does not provide the complete path from the root directory.
Instead, it refers to the file or directory based on the current location or context.
Examples of relative paths: documents/file.txt, ../images/image.jpg.
The .. notation refers to the parent directory, while . refers to the current directory.
Key differences between absolute and relative paths:
| Absolute Paths | Relative Paths | |
| Length and Specificity | Absolute paths are complete and specific, providing the full path from the root directory. | Relative paths are shorter and depend on the current working directory. |
| Portability | Absolute paths may not be portable if the file system structure differs. | Relative paths can be more portable as they adapt to different directory structures and can be used across different systems |
| Contextual Dependancy | Absolute paths always point to the same location regardless of the current working directory. | Relative paths depend on the current working directory, so the same relative path can refer to different files or directories depending on the location from which it is executed. |
| Ease of Use | Absolute paths are useful when you need to refer to specific locations or when writing scripts that require consistent paths. | Relative paths are often more convenient for navigating within a directory hierarchy. |
18. How do you create a new user account in Linux using the command-line?
To create a new user account in Linux using the command-line, you can use the adduser or useradd.
Here is an example of the above command:
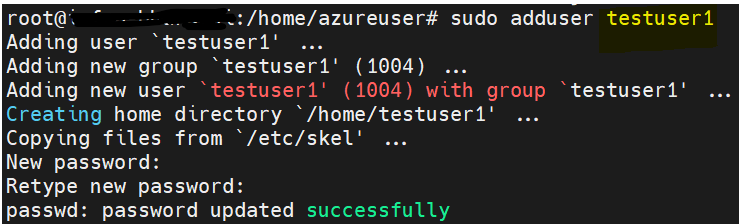
While creating user, you will be asked to enter password the user but while entering the same it won’t be visible to you.
19. How many users are there in Linux command?
To check the number of users in a Linux system using the command-line, you can use the cat command in combination with the /etc/passwd file. Each user account on the system is listed in this file. Here’s how you can do it: cat /etc/passwd | wc -l
This command reads the contents of the /etc/passwd file and pipes it to the wc -l command. The wc command with the -l option counts the number of lines in the input.
20. What is the Linux command to change your password?
To change your password in Linux using the command-line, you can use the passwd command.
To change the password for another user in Linux using the command-line, you need to execute the passwd command as the root user or with root privileges.
21. What is sed command in Linux?
The sed command in Linux is a powerful text-processing utility that stands for “stream editor.” It is primarily used for performing transformations on text files, such as search-and-replace operations, insertion or deletion of lines, and other editing tasks.
The sed command reads input files line by line, applies specified commands to each line, and then outputs the modified text. The commands in sed are based on regular expressions, which allow for flexible pattern matching and manipulation of the input text.
22. Explain the concept of environment variables in Linux.
In Linux, environment variables are a fundamental part of the operating system’s environment. They are dynamic values that can affect the behavior of processes and programs running on the system. Environment variables are essentially named variables that store information about the system or user environment.
Each environment variable has a name and a value associated with it. The name is typically uppercase, and the value can be any string of characters. Some environment variables are predefined by the system, while others can be created and customized by users.
Here are a few important aspects of environment variables in Linux:
System-wide and user-specific variables: Environment variables can be set at the system level or for specific user accounts. System-wide variables affect all users on the system, while user-specific variables are specific to a particular user account.
Inherited values: When a new process is created, it inherits the environment variables from its parent process. This allows variables set in one process to be accessed by child processes. This inheritance makes environment variables useful for configuring the behavior of programs and scripts.
Default variables: Linux provides some default environment variables that are commonly used by various programs. For example, the PATH variable contains a list of directories where the system searches for executable programs.
Customization and modification: Users can modify or create their own environment variables to suit their needs. These variables can store information such as paths to custom binaries, configuration settings, API keys, or any other data relevant to the user’s environment.
Setting and accessing variables: Environment variables can be set using the export command in the shell. For example, export MY_VARIABLE=value sets the variable MY_VARIABLE with the value “value”. The echo command with the $ symbol can be used to access the value of an environment variable. For example, echo $MY_VARIABLE will display the value of MY_VARIABLE.
23. How do you recursively delete directories and files in Linux using the command-line?
To recursively delete directories and files in Linux using the command-line, you can use the rm command with the -r (or –recursive) option. This option tells rm to remove directories and their contents recursively.
Here is the basic syntax: rm -r directory_path
24. What is the purpose of the awk command in Linux?
The awk command in Linux is a versatile and powerful text-processing tool. It allows you to manipulate and extract data from structured text files, such as log files, CSV files, and configuration files. The awk command operates on a line-by-line basis, reading the input file(s) and executing user-defined patterns and actions.
25. What is the use of who command in Unix?
The who command in Unix is used to display information about users who are currently logged in to the system. It provides details such as the username, terminal or login location, login time, and duration of the session.
The basic syntax of the who command is as follows: who [options]
26. Why we use whois command in Linux?
The whois command in Linux is used to retrieve information about domain names, IP addresses, and various other network-related information from the WHOIS database. WHOIS is a protocol and database used to store and retrieve registration and ownership details of domain names, IP addresses, and network blocks.
27. How do you recursively change file permissions in Linux using the command-line?
To recursively change file permissions in Linux using the command-line, you can use the chmod command with the -R (or –recursive) option. This option allows you to apply permissions changes to files and directories recursively.
The basic syntax to recursively change file permissions using chmod is as follows:
chmod -R permissions directory
Replace permissions with the desired permissions you want to set, and directory with the path to the directory or file for which you want to change the permissions.
28. How do you list all installed packages on a Debian-based Linux system using the command-line?
To list all installed packages on a Debian-based Linux system using the command-line, you can use the dpkg command. Here is how we can:
dpkg –list
The dpkg command with the –list option displays a comprehensive list of all installed packages on your Debian-based system. This list includes both the installed packages and their versions.
29. How do you list all installed packages on a CentOS-based Linux system using the command-line?
On CentOS-based Linux systems, you can use the yum command to list all installed packages. Here’s how: yum list installed
The yum command with the list installed option will display a list of all installed packages on your CentOS-based system. This list includes the package name, version, and repository information
30. Explain the concept of process scheduling in Linux.
Process scheduling in Linux refers to the mechanism by which the Linux kernel decides which processes should run, when they should run, and for how long. The goal of process scheduling is to efficiently allocate CPU time to processes and ensure fair and responsive execution of various tasks running on a system.
31. How do you count the number of lines in a file in Linux using the command-line?
To count the number of lines in a file in Linux using the command-line, you can use the wc (word count) command with the -l option. Here’s how: wc -l filename
Replace filename with the name of the file you want to count the lines of.
The wc command with the -l option counts the number of lines in the specified file and displays the result on the terminal.
32. What is the use of the tail command in Linux?
The tail command in Linux is used to display the last few lines (or a specified number of lines) from a file or output stream. It is particularly useful for viewing the end of log files, monitoring real-time updates, and extracting relevant information from large files.
By default, it will show last 10 lines of a file.
33. How do you navigate to the home directory in Linux using the command-line?
To navigate to the home directory in Linux using the command-line, you can use the cd command with the tilde (~) character, which is a shorthand representation of the home directory.
Here’s how you can do it: cd ~
By running this command, you will be directly taken to your home directory.
Alternatively, you can explicitly specify the home directory path using the $HOME environment variable:
34. Explain the concept of process communication in Linux.
In Linux, process communication refers to the mechanisms and techniques that allow processes to exchange data, synchronize their activities, and coordinate their execution. Processes may need to communicate with each other to share information, coordinate tasks, or collaborate in performing a particular function.
35. How do you display the last few lines of a file in Linux using the command-line?
To display the last few lines of a file in Linux using the command-line, you can use the tail command with the -n option. Here’s how: tail -n <number_of_lines> <filename>
Replace <number_of_lines> with the desired number of lines you want to display, and <filename> with the name of the file you want to view.
36. What is the use of the sort command in Linux?
The sort command in Linux is used to sort the lines of text files or input streams in a specified order. It takes input, sorts it line by line, and produces the sorted output. The sort command is highly versatile and provides various options to customize the sorting behavior.
37. Explain the concept of standard input, output, and error streams in Linux.
In Linux, standard input (stdin), standard output (stdout), and standard error (stderr) are three standard communication channels used by programs to interact with the environment and exchange data. They are often abbreviated as STDIN, STDOUT, and STDERR, respectively. Understanding these streams is crucial for managing command-line programs and redirecting input/output.
Here’s an explanation of each stream:
| Standard Input (stdin) | Standard Output (stdout) | Standard Error (stderr) | |
| 1 | STDIN is the default input stream where a program reads input from the user or other programs. | STDOUT is the default output stream where a program sends its normal output. | STDERR is the default error stream where a program sends error messages and diagnostic output. |
| 2 | By default, STDIN is connected to the keyboard, allowing users to enter data through the command-line interface. | By default, STDOUT is connected to the terminal or console, and the program’s output is displayed there. | By default, STDERR is also connected to the terminal or console, and error messages are displayed there. |
| 3 | Programs can read input from STDIN using functions or system calls specifically designed for input operations. | Programs can write output to STDOUT using functions or system calls specifically designed for output operations. | Programs can write error messages to STDERR using functions or system calls specifically designed for error output. |
| 4 | STDOUT can be redirected to a file or another program using output redirection. | STDERR can be redirected separately from STDOUT, allowing errors to be captured and handled separately from normal program output. |
38. What is the purpose of the kill command in Linux?
The kill command in Linux is used to send signals to processes, allowing you to manage their execution and control their behavior. Despite its name, the primary purpose of the kill command is not necessarily to terminate or kill processes but rather to send signals to them.
Here are some key aspects of the kill command:
Sending Signals: The kill command is commonly used to send signals to processes. The default signal sent by kill is SIGTERM (termination signal), which requests a process to terminate gracefully. However, you can specify different signals using the -s or –signal option.
Process Termination: The kill command is often used to terminate processes by sending the SIGTERM signal (signal number 15). This signal requests a process to exit gracefully, allowing it to perform cleanup tasks before terminating. To terminate a process, you need to know its process ID (PID) and use the -15 or -TERM option with kill.
Signal Handling: Processes can handle signals differently based on their implementation. They can choose to ignore certain signals or define custom actions to be executed when specific signals are received. Common signals include SIGKILL (forceful termination), SIGSTOP (stop process execution), and SIGCONT (resume process execution).
Process Control: Besides terminating processes, the kill command can be used to control process behavior. For example, sending the SIGSTOP signal temporarily suspends a process, while sending the SIGCONT signal resumes its execution.
39. How do you create a new group in Linux using the command-line?
To create a new group in Linux using the command-line, you can use the groupadd command. Here’s how: sudo groupadd <groupname>
Replace with the desired name of the new group.
The groupadd command creates a new group with the specified name. By default, the group ID (GID) is assigned automatically, but you can also specify a specific GID using the -g option followed by the desired GID number.
After executing the command, the new group will be created on the system. You can verify the creation of the group by checking the /etc/group file or using the getent group command.
Note that creating a group typically requires administrative privileges, so you may need to prefix the groupadd command with sudo and enter your password.
40. Explain the difference between a root user and a regular user in Linux.
In Linux, there are two main types of users: the root user and regular users. These users have distinct privileges, responsibilities, and access levels.
Here’s an explanation of the differences between them:
| Root User (Superuser/Administrator) | Regular User (Non-privileged User) | |
| 1 | The root user is also known as the superuser or administrator. | Regular users are standard user accounts created on the system. |
| 2 | The root user has unrestricted access to all commands, files, and system resources on the Linux system. | Regular users have limited privileges and cannot perform administrative tasks or modify critical system files. |
| 3 | The root user can perform administrative tasks, modify system configuration files, install, and remove software, manage users and permissions, and execute any command with full privileges. | They have access only to their own files and directories, as well as other resources where specific permissions have been granted. |
| 4 | The root user has the highest level of control and can make critical changes that affect the entire system. | Regular users can execute common applications, run commands, create and modify their own files, and interact with the system within their permitted scope. |
| 5 | It is crucial to exercise caution when using the root user privileges, as any mistakes or unintended actions can have significant consequences. | They require elevated privileges (typically by providing the root user’s password) to perform administrative tasks or access sensitive system resources. |
41. How do you check the CPU temperature in Linux using the command-line?
To check the CPU temperature in Linux using the command-line, you can use various tools depending on your system and the availability of specific commands. Here are a few commonly used methods:
1. Using lm-sensors:
a. Install lm-sensors if not already installed by running sudo apt-get install lm-sensors (for Debian/Ubuntu-based systems).
b. Run the sensors command to display the temperature readings.
c. The output will provide temperature information for different components, including the CPU.
2. Using /sys filesystem:
a. Navigate to the /sys/class/thermal/ directory.
b. Inside this directory, there are subdirectories like thermal_zone0, thermal_zone1, etc., representing different temperature sensors.
c. Each subdirectory contains a file called temp that provides the temperature in millidegrees Celsius.
d. To check the CPU temperature, you can run a command like cat /sys/class/thermal/thermal_zone0/temp.
3. Using third-party tools:
a. There are various third-party command-line tools available that provide more detailed information about CPU temperature, such as s-tui, htop, psensor, and conky.
b. These tools may require installation and configuration, depending on your Linux distribution.
42. What is the use of the tail -f command in Linux?
The tail -f command in Linux is used to monitor a file in real-time and continuously display new lines appended to it. The -f option stands for follow and is commonly used for log files and real-time monitoring of file updates.
43. How do you concatenate files in Linux using the command-line?
To concatenate (combine) files in Linux using the command-line, you can use the cat command. Here’s how: cat file1 file2 > merged_file
Replace file1 and file2 with the names of the files you want to concatenate. The > symbol redirects the output to a new file named merged_file, which will contain the concatenated content of file1 and file2.
44. Explain the concept of file system hierarchy in Linux.
The file system hierarchy in Linux refers to the organization and structure of files and directories within the Linux operating system. It defines a standardized layout and directory structure that helps organize and manage the system’s files, configuration files, libraries, executable, and other resources.
Here are the key directories and their purposes in the Linux file system hierarchy:
/ (Root Directory): The root directory serves as the starting point of the file system hierarchy. It contains all other directories and files in the system.
/bin (Binary Programs): This directory contains essential executable files and commands needed for basic system operations. Common commands and utilities used by all users, such as ls, cp, rm, are located here.
/boot (Boot Files): The boot directory contains files related to the system’s boot process, including the Linux kernel, initial RAM disk (initrd), boot loader configurations (e.g., GRUB), and other boot-related files.
/dev (Device Files): The dev directory contains special device files that represent hardware devices in the system. These files provide a way to communicate with and access hardware devices such as disks, terminals, printers, and more.
/etc (System Configuration Files): The etc directory contains system-wide configuration files. It includes various configuration files related to system services, network settings, user accounts, software applications, and other system-wide settings.
/home (User Home Directories): Each user on the system has their own home directory located within the home directory. User-specific files and directories, such as documents, personal settings, and configurations, are stored here.
/lib and /lib64 (Shared Libraries): These directories contain shared libraries needed by executable files in the system. The /lib directory contains shared libraries for 32-bit systems, while /lib64 contains libraries for 64-bit systems.
/media and /mnt (Mount Points): These directories serve as mount points for removable media (e.g., USB drives, optical disks) and manually mounted file systems, respectively.
/opt (Optional Software): The opt directory is used for installing optional software packages or third-party applications. It provides a place to install software that is not part of the core system distribution.
/tmp (Temporary Files): The tmp directory is used for storing temporary files created by processes and the system. These files are typically deleted upon system reboot.
/usr (User Programs and Data): The usr directory contains the majority of user programs, libraries, and data files. It is subdivided into several sub-directories, such as /usr/bin, /usr/lib, /usr/share, and more.
/var (Variable Files): The var directory contains variable files that change in size and content during system operation. It includes log files, spool directories for print queues, cache files, database files, and other variable data.
The Linux file system hierarchy follows the Filesystem Hierarchy Standard (FHS) or Linux Standard Base (LSB) guidelines, which ensure consistency and compatibility across different Linux distributions. Understanding the file system hierarchy helps users and administrators locate files, manage system configurations, and maintain organization and structure within the Linux operating system.
45. What is the purpose of the curl command in Linux?
The curl command in Linux is a versatile tool used for performing various network-related tasks. It stands for Client for URLs and is primarily designed for making HTTP requests and retrieving data from URLs. However, curl can handle a wide range of protocols and supports numerous features.
46. How do you check the network connectivity to a remote host in Linux using the command-line?
To check network connectivity to a remote host in Linux using the command-line, you can use the ping command.
Here’s the basic syntax: ping <hostname or IP address>
For example, if you want to check the connectivity to Google’s DNS server at IP address 8.8.8.8, you would run: ping 8.8.8.8
47. Explain the difference between a shell variable and an environment variable in Linux.
In Linux, both shell variables and environment variables are used to store information that can be accessed and utilized by the operating system and various processes.
However, there is a distinction between the two:
| Shell Variables | Environment Variables | |
| 1 | Shell variables are specific to the current shell session or instance. | Environment variables are accessible by all processes running on the system, including the shell and its child processes. |
| 2 | They are created and managed by the shell (e.g., Bash, Zsh) and are only accessible within the shell or its child processes. | They are set in the system environment and can be accessed by any program or process that is executed. |
| 3 | Shell variables are primarily used for storing temporary or local data within a script or a specific shell session. | Environment variables are often used to define system-wide settings, configuration options, or values required by various programs. |
| 4 | They have a local scope and are not accessible by other running programs or processes. | When a new process is created, it inherits a copy of the environment variables from its parent process. |
| 5 | Environment variables have a global scope and can be accessed and modified by any process unless explicitly restricted. |
48. What is the purpose of the head command in Linux?
The head command in Linux is used to display the beginning or the first few lines of a text file or input stream. Its primary purpose is to preview the content of a file or quickly examine the initial portion of a file without displaying the entire file. By default, it displays the first 10 lines of a file, but you can specify a different number of lines using command options.
The syntax of the head command is as follows: head [options] [file(s)]
49. How do you recursively copy directories and files in Linux using the command-line?
To recursively copy directories and files in Linux using the command-line, you can use the cp command with the -r or -R option.
Here’s the basic syntax: cp -r <source> <destination>
The -r or -R option stands for recursive and allows the cp command to copy directories and their contents recursively.
50. How do you find the process ID (PID) of a running process in Linux using the command-line?
To find the Process ID (PID) of a running process in Linux using the command-line, you can use the pgrep, pidof, or ps commands.
Here are the basic usage examples for each command:
1. pgrep Command
The pgrep command allows you to search for processes based on their name or other attributes and retrieve their PIDs.
Here is the general syntax: pgrep <process_name> (Example: pgrep chrome)
This command will return the PID(s) of the running process(es) with the name chrome.
2. pidof Command
The pidof command is specifically designed to find the PID of a running process based on its name.
Here is the general syntax: pidof <process_name> (Example: pidof apache2)
This command will display the PID of the running process(es) with the name apache2.
3. ps Command
The ps command is a versatile command for displaying information about processes. By combining it with other options and filters, you can find the PID of a specific process.
Here is the general syntax: ps -ef | grep <process_name> (Example: ps -ef | grep sshd)
This command will list all processes containing the name sshd and their corresponding PIDs.
All three commands mentioned above provide ways to find the PID of a running process in Linux. Choose the one that suits your needs and preference.
Wrapping Up Top 50 Linux Questions and Answers
So, in this article, we explored on various important Linux questions and answers. We will continue on this topics on next part.
Reference:
- https://www.linuxfoundation.org/blog/blog/classic-sysadmin-how-to-check-disk-space-on-linux-from-the-command-line
- If you wish to explore more on Linux on this website, click here.