In Linux, the term “filters in Linux” typically refers to commands that are used to process or manipulate text data, usually by taking input from standard input (stdin), performing a transformation or filtering operation, and then producing the modified output to standard output (stdout). These commands are designed to work in a pipeline, where the output of one command serves as the input for the next command.
Filters in Linux are often used to extract specific information from files, format data, search for patterns, sort data, perform arithmetic calculations, and much more.
Some commonly used filters in Linux include:
- tee
- grep
- cut
- tr
- wc
- sort
- uniq
We will discuss on the above topics one by one with its example.
The “tee” command in filters in Linux is a useful utility that reads input from the standard input (stdin) and writes it both to the standard output (stdout) and one or more files simultaneously. It allows you to redirect output to a file while still displaying it on the terminal.
The basic syntax of the “tee” command is as follows:
Syntax: tee [OPTION]… [FILE]…
Here, “[OPTION]” represents any optional flags or parameters that modify the behavior of the command, and “[FILE]” represents the name of the file(s) to which you want to write the input.
Here is an example of “tee” command:

so, in the above example, “tee” command helped us in copying the data from temp.txt file to temp1.txt file and in revers ways.
The “grep” command in filters in Linux is a powerful tool used for searching and filtering text based on patterns. It stands for “Global Regular Expression Print”. “grep” searches input files or the output of other commands for lines that match a specified pattern and prints those lines to the standard output.
Here is the basic syntax of “grep” command:
Syntax: grep [OPTIONS] PATTERN [FILE…]
Here, [OPTIONS] represents any optional flags or parameters that modify the behavior of the command, PATTERN is the regular expression or string you want to search for, and [FILE…] represents the name of the file(s) to search in. If no file is specified, “grep” reads from the standard input (stdin).
Some common uses of the “grep” command are:
Searching for a pattern in a file:
Syntax: grep ‘pattern’ filename
Here is an example of “grep” command searching for a pattern in a file:

This command searches for lines in “temp.txt” that match the specified pattern and displays those lines on the terminal. Here we tried searching for matching content with “Line”.
Searching for a pattern in multiple files:
Syntax: grep ‘pattern’ file1 file2 file3
Here is an example of “grep” command searching for a pattern in multiple files.

This command searches for lines matching the pattern “Line2” in temp.txt, temp1.txt displaying the matching lines on the terminal.
Ignoring case sensitivity:
Syntax: grep -i ‘pattern’ filename (Here ‘i’ option performs a case-insensitive search, so the pattern can match regardless of letter case.)
Here is an example of “grep” command ignoring case sensitivity.

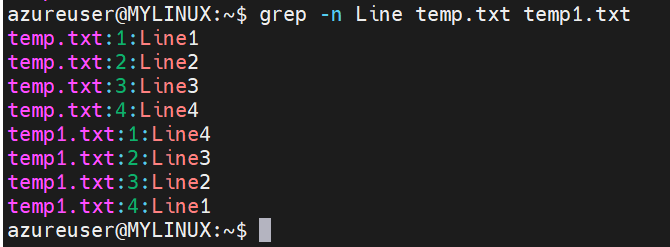
Displaying line numbers:
Syntax: grep -n ‘pattern’ filename
The “-n” option displays line numbers along with the matching lines, making it easier to locate specific occurrences.
Here is an example of “grep” command displaying line numbers along with line.
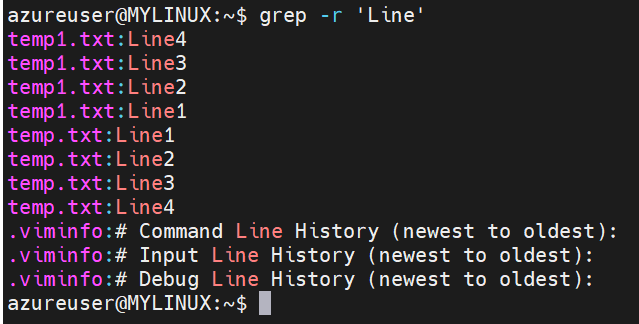
Searching recursively in directories:
Syntax: grep -r ‘pattern’ directory (The -r option enables recursive searching in directories. grep searches for the pattern in all files within the specified directory and its sub-directories.)
Here is an example of searching recursively in directories.
The “cut” command in filters in Linux is used to extract specific sections or columns from lines of input or files. It is particularly useful for working with structured data where you want to isolate specific fields or portions of each line.
The basic syntax of the cut command is as follows:
Syntax: cut OPTION… [FILE]…
Here, “[OPTION]” represents any optional flags or parameters that modify the behavior of the command, and “[FILE]” represents the name of the file(s) from which you want to extract data. If no file is specified, “cut” reads from the standard input (stdin).
The “tr” command in filters in Linux stands for Translate and is a powerful utility used for translating or deleting characters in a given input. It is often used to perform simple character-level transformations on text data.
The basic syntax of the tr command is as follows: tr [OPTION]… SET1 [SET2]
Here, [OPTION] represents any optional flags or parameters that modify the behavior of the command, SET1 specifies the characters to be replaced, and SET2 specifies the replacement characters. If SET2 is not provided, “tr” will delete the characters specified in SET1.
Some common uses of the “tr” command are:
Character substitution: tr ‘SET1’ ‘SET2’ < input.txt
This command replaces characters from SET1 with the corresponding characters from SET2 in the input file input.txt. The length of SET2 should match the length of SET1 or be shorter.
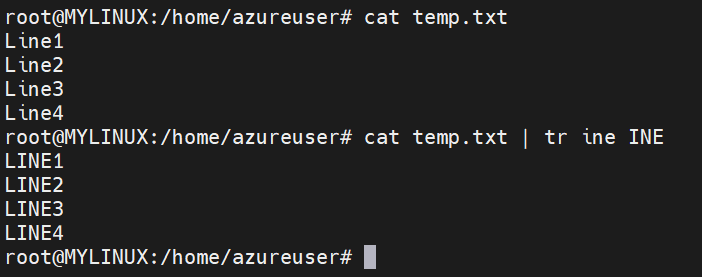
In the above example, we substituted the characters ‘ine’ to ‘INE‘.
Character deletion:
Syntax: tr -d ‘SET1’ < input.txt
The ‘-d’ option instructs ‘tr’ to delete the characters specified in ‘SET1’ from the input file, effectively removing them.
Here is an example of character deletion:
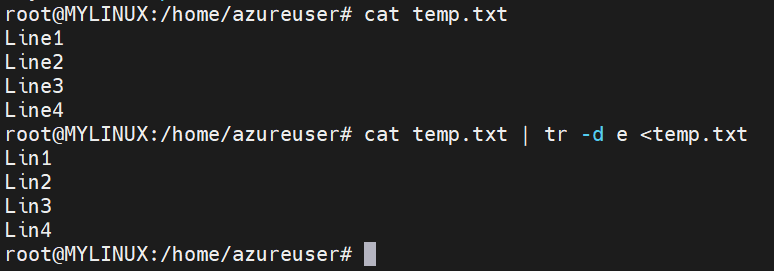
In this example, we deleted ‘e’ character.
The “wc” command in filters in Linux is a handy utility that stands for “word count.” It is used to count the number of lines, words, and characters in a given input or file.
The basic syntax of the wc command is as follows: wc [OPTION]… [FILE]…
Here, [OPTION] represents any optional flags or parameters that modify the behavior of the command, and [FILE] represents the name of the file(s) for which you want to count the lines, words, and characters. If no file is specified, “wc” reads from the standard input (stdin).
Here is an example of “wc” command in Linux:

Some common uses of the “wc” command are:
Counting lines:
Syntax: wc -l filename (This command counts the number of lines in the specified file and displays the result.)
Here is an example “wc -l” command:

Counting words:
Syntax: wc -w filename (This command counts the number of words in the specified file and displays the result. Words are defined as consecutive sequences of non-whitespace characters.)
Here is an example of “wc -w” command:

Counting characters:
Syntax: wc -c filename (This command counts the number of characters (bytes) in the specified file and displays the result. This includes all characters, including spaces, tabs, and newline characters.)
Here is an example of “wc -c” command:

The “sort” command in filters in Linux is a powerful utility that is used to sort lines of text alphabetically or numerically. It reads input from a file or standard input and outputs the sorted lines to the standard output.
The basic syntax of the sort command is as follows: sort [OPTION]… [FILE]… Here, [OPTION] represents any optional flags or parameters that modify the behavior of the command, and [FILE] represents the name of the file(s) to sort. If no file is specified, “sort” reads from the standard input (stdin).
Here is an example of “sort” command:
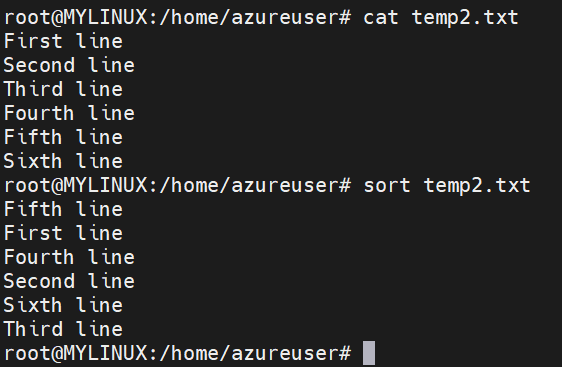
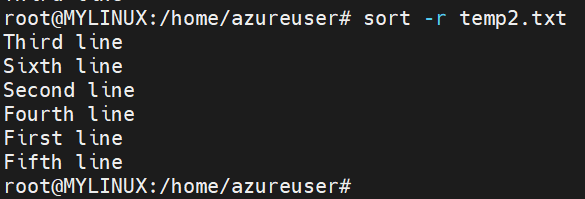
Reversing the sort order:
Syntax: sort -r filename (The ‘-r’ option reverses the sort order, sorting lines in descending order instead of ascending order.
Here is an example of reversing the sort order:
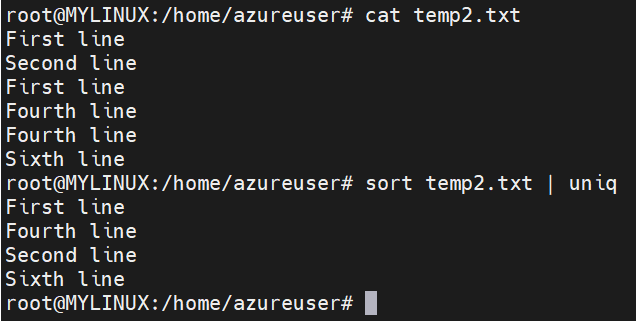
The “uniq” command in filters in Linux is a useful utility that is used to filter out or identify unique or repeated lines of text in a sorted input. It compares adjacent lines and removes or displays duplicates, depending on the options used.
The basic syntax of the “uniq” command is as follows: uniq [OPTION]… [FILE]…
Here, [OPTION] represents any optional flags or parameters that modify the behavior of the command, and [FILE] represents the name of the file(s) to process. If no file is specified, “uniq” reads from the standard input (stdin).
Here is an example of “uniq” command:
Wrapping up
So, in this section we learnt about Filters in Linux. Filters are command-line utilities that process and manipulate data in a streaming manner. They accept input from standard input or files and produce output to standard output. Filters are designed to perform specific tasks and can be combined using pipes to create powerful data processing pipelines.
Filters in Linux can be used for tasks like searching, sorting, filtering, transforming, and formatting text or binary data. Filters are an essential part of the Linux command-line ecosystem, providing a flexible and efficient way to manipulate data, automate tasks, and build complex workflows in a modular and scalable manner. If you wish to explore more on this topic, please follow here or wish to learn shell history in Linux, click here.